A. Kendall, M. Grimes, and R. Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. In IEEE International Conference on Computer Vision (ICCV), 2015.
Dataset

PoseNet,第一行是原图,第二行是根据所估计的相机姿态做 3D重建后的场景图,第三行是原图和重建后的场景的重叠。
主要思想
首次提出一种利用卷积神经网络对相机6维姿态进行端到端的估计的方法,输入单张RGB图片,实时回归出当前的相机6维姿态。网络架构是基于GoogLeNet Inceptionv1 进行修改的,通过将网络最后3个softmax分类器替换为3个全连接层,分别对相机位置 \(x\) (3维) 和 旋转 \(q\) (4维,采用四元数表示) 进行归回;并在最后的回归层前面增加一个大小为2048的全连接层,用于提取区域特征。网络可实时端到端的回归出相机当前姿态 \(p = [x, q]\) ,损失函数如下:
\[
loss(I) = ||\hat{x} - x||_2 + \beta||\hat{q} - \frac{ q}{|| q||}||_2
\]
由于位置 \(x\) 和旋转 \(q\) 之间存在着尺度问题,所以其中的 \(\beta\) 超参数是用于平衡两个loss的,需要根据场景的大小进行相应的手动调整。
实验细节
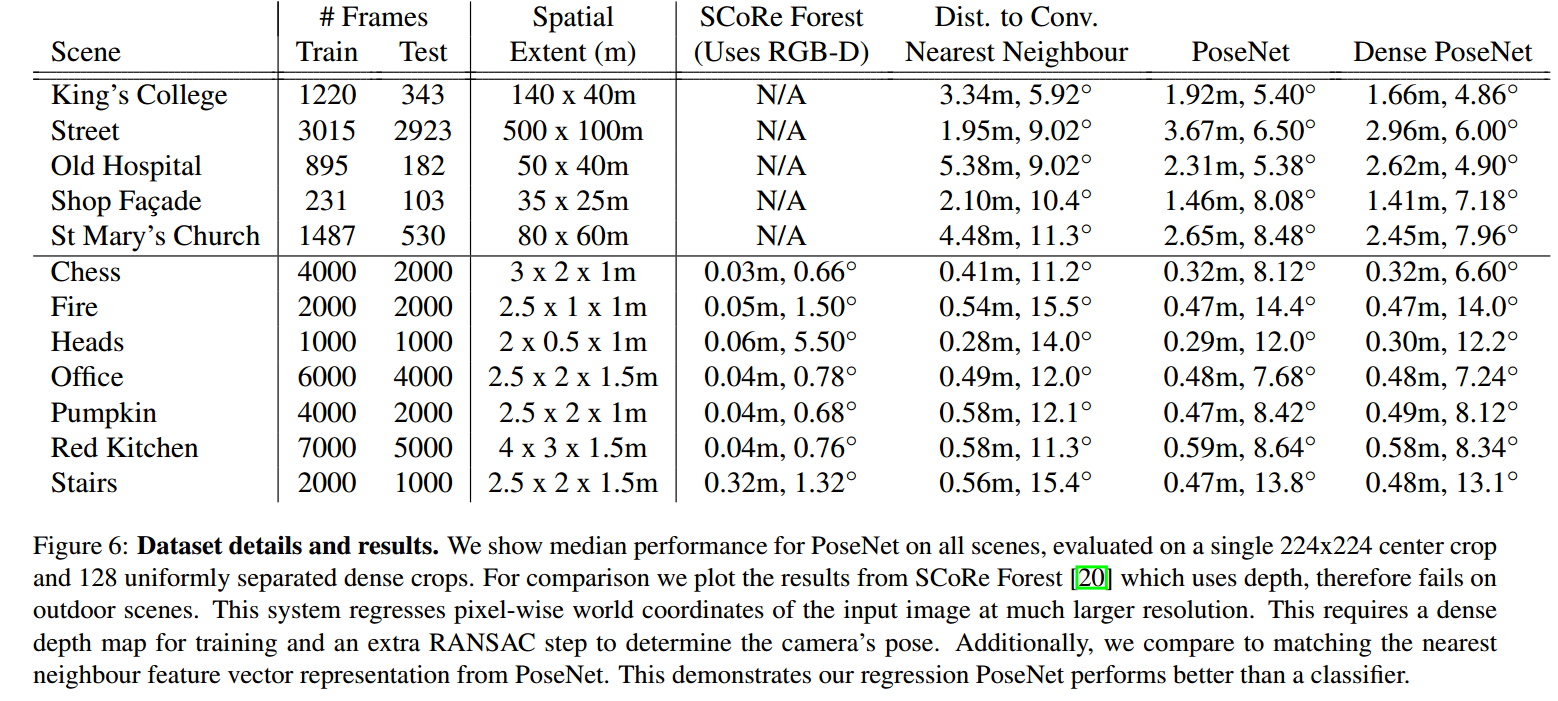
训练数据由5个大型室外场景Cambridge Landmarks以及7个小型室内场景7Scenes组成,所有图片对应的相机姿态ground truth 都是通过 SFM(Structure from motion) 技术计算得到。训练时,先对每张图片按长宽比进行resize,将短边resize到256,即256x455 (7Scenes数据集resize到255x340),让后将resize后的所有训练图片计算均值。训练时,将训练图片256x455减去均值再进行随机剪裁到224x224再输入CNN。测试时,将测试图片256x455减去均值再进行中心剪裁到224x224再输入到CNN。
实验结果
实验结果显示,在室外场景误差大约为2m, 6°,室内场景大约为0.5m,10°,单张图片测试时间为5ms
待改进问题
PoseNet 需要手动调节一个超参数 \(\beta\) ,并且对于出现障碍物的场景定位效果不精确。
Reference