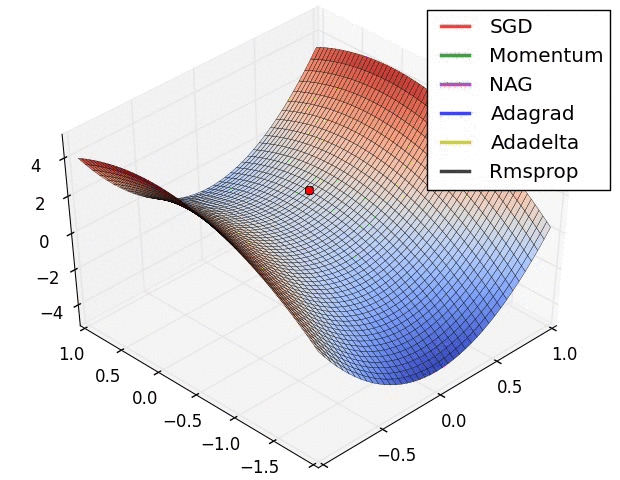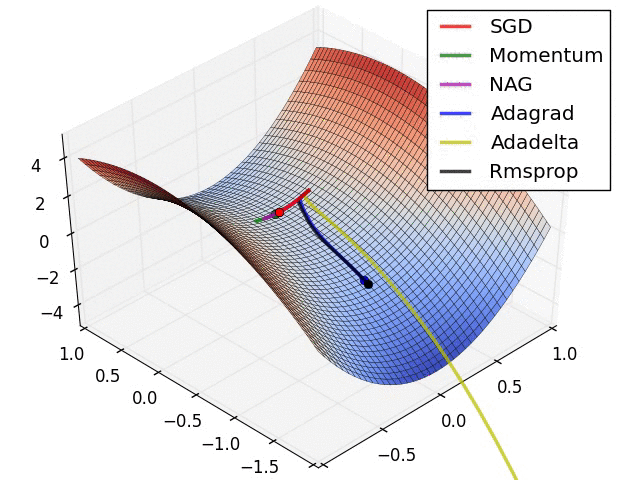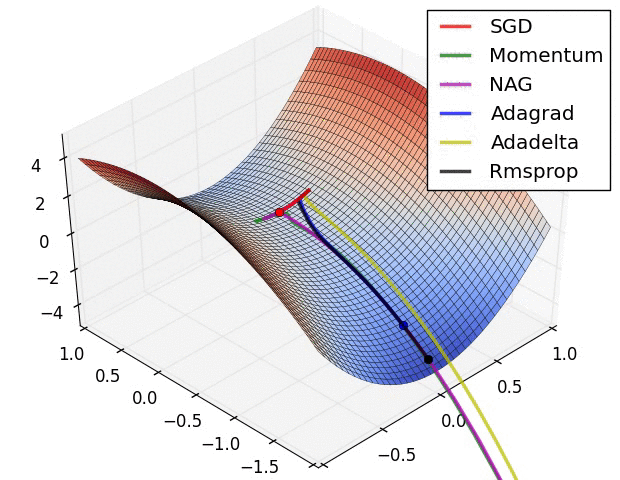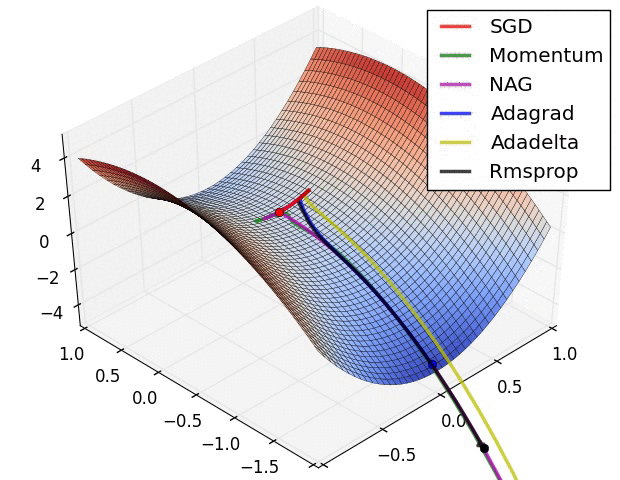
1. 引言
最优化问题是计算数学中最为重要的研究方向之一。而在深度学习领域,优化算法的选择也是一个模型的重中之重。即使在数据集和模型架构完全相同的情况下,采用不同的优化算法,也很可能导致截然不同的训练效果。
梯度下降是目前神经网络中使用最为广泛的优化算法之一。为了弥补朴素梯度下降的种种缺陷,研究者们发明了一系列变种算法,优化算法经历了 SGD -> SGDM -> NAG -> AdaGrad -> AdaDelta -> Adam -> NAdam 这样的发展历程。从最初的 SGD (随机梯度下降) 逐步演进到 NAdam。然而,许多学术界最为前沿的文章中,都并没有一味使用 Adam/NAdam 等公认“好用”的自适应算法,很多甚至还选择了最为初级的 SGD 或者 SGD with Momentum 等。
本文旨在梳理深度学习优化算法的发展历程,并在一个更加概括的框架之下,对优化算法做出分析和对比。
2. Gradient Descent
梯度下降是指,在给定待优化的模型参数 \(\theta \in \mathbb{R}^d\) 和目标函数 \(J(\theta)\) 后,算法通过沿梯度 \(\nabla_\theta J(\theta)\)的相反方向更新 \(\theta\) 来最小化 \(J(\theta)\) 。学习率 \(\eta\) 决定了每一时刻的更新步长。对于每个epoch \(t\) ,我们可以用下述步骤描述梯度下降的流程:
(1) 计算目标函数关于参数的梯度
\[
g_t = \nabla_\theta J(\theta)
\]
(2) 根据历史梯度计算一阶和二阶动量
\[
m_t = \phi(g_1, g_2, \cdots, g_t)
\]
\[ v_t = \psi(g_1, g_2, \cdots, g_t) \]
(3) 计算当前时刻的下降梯度(步长) \(\frac{m_t}{\sqrt{v_t + \epsilon}}\) ,并根据下降梯度更新模型参数
\[
\theta_{t+1} = \theta_t - \frac{m_t}{\sqrt{v_t + \epsilon}}
\]
其中, \(\epsilon\) 为平滑项,防止分母为零,通常取 \(1e-8\) 。
注意:本文提到的步长,就是下降梯度。
3. Gradient Descent 和其算法变种
根据以上框架,我们来分析和比较梯度下降的各变种算法。
4. Vanilla SGD
朴素 SGD (Stochastic Gradient Descent) 最为简单,没有动量的概念,即
\[
m_t = \eta g_t
\]
\[ v_t = I^2 \]
\[ \epsilon = 0 \]
这时,更新步骤就是最简单的
\[
\theta_{i+1}= \theta_t - \eta g_t
\]
缺点:
- 收敛速度慢,而且可能会在沟壑的两边持续震荡
- 容易停留在一个局部最优点
- 如何合理的选择学习率也是 SGD 的一大难点
5. SGD with Momentum
为了抑制SGD的震荡,SGD-M认为梯度下降过程可以加入惯性(动量) Momentum[3],加速 SGD 在正确方向的下降并抑制震荡。就好像下坡的时候,如果发现是陡坡,那就利用惯性跑的快一些。其在SGD的基础上,引入了一阶动量,然后进行更新:
\[
m_t = \gamma m_{t-1} + \eta g_t \\
\theta_{t+1}= \theta_t - m_t
\]
即在原步长(SGD中是\(\eta g_t\)) 之上,增加了与上一时刻动量相关的一项 \(\gamma m_{t-1}\),目的是结合上一时刻步长(下降梯度), 其中 \(m_{t-1}\) 是上一时刻的动量,\(\gamma\) 是动量因子。也就是说,\(t\) 时刻的下降方向,不仅由当前点的梯度方向决定,而且由此前累积的下降方向决定,\(\gamma\) 通常取 0.9 左右。这就意味着下降方向主要是此前累积的下降方向,并略微偏向当前时刻的下降方向。这使得参数中那些梯度方向变化不大的维度可以加速更新,并减少梯度方向变化较大的维度上的更新幅度。由此产生了加速收敛和减小震荡的效果。
 |
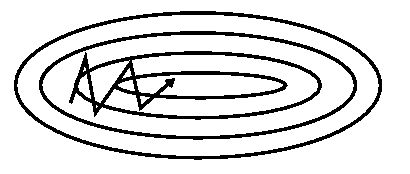 |
|---|---|
| 图 1(a): SGD | 图 1(b): SGD with momentum |
从图 1 中可以看出,引入动量有效的加速了梯度下降收敛过程。
6. Nesterov Accelerated Gradient
SGD 还有一个问题是困在局部最优的沟壑里面震荡。想象一下你走到一个盆地,四周都是略高的小山,你觉得没有下坡的方向,那就只能待在这里了。可是如果你爬上高地,就会发现外面的世界还很广阔。因此,我们不能停留在当前位置去观察未来的方向,而要向前一步、多看一步、看远一些。
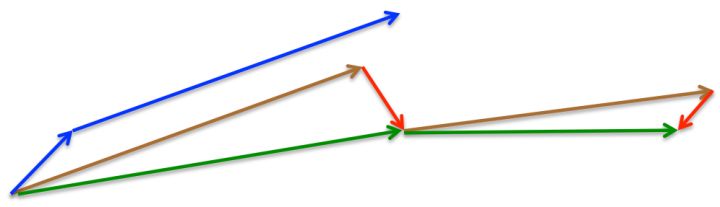
NAG全称Nesterov Accelerated Gradient,则是在SGD、SGD-M的基础上的进一步改进,算法能够在目标函数有增高趋势之前,减缓更新速率。我们知道在时刻 \(t\) 的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算,那与其看当前梯度方向,不如先看看如果跟着累积动量走了一步后,那个时候再怎么走。因此,NAG在步骤1,不计算当前位置的梯度方向,而是计算如果按照累积动量走了一步,那个时候的下降方向:
\[
g_t = \nabla_\theta J(\theta - \gamma m_{t-1}) \tag{1}
\]
参考图2理解:最初,SGD-M先计算当前时刻的梯度(短蓝向量)和累积动量 (长蓝向量)进行参数更新。改进的方法NAG,先利用累积动量计算出下一时刻的 \(\theta\) 的近似位置 \(\theta - \gamma m_{t-1}\)(棕向量),并根据该未来位置计算梯度(红向量)公式(1),然后使用和 SGD-M 中相同的方式计算当前时刻的动量项(下降梯度),进而得到完整的参数更新(绿向量),公式(2)即将该未来位置的梯度与累积动量计算当前时刻的动量项(下降梯度):
\[
\begin{equation}
\begin{split}
m_t &= \gamma m_{t-1} + \eta g_t \\
&= \gamma m_{t-1} + \eta \nabla_\theta J(\theta - \gamma m_{t-1})
\end{split}
\end{equation} \tag{2}
\]
更新参数:
\[
\theta_{t+1} = \theta_t - m_t \tag{3}
\]
这种计算梯度的方式可以使算法更好的「预测未来」,提前调整更新速率。
注意:
累积动量指的是上一时刻的动量乘上动量因子: \(\gamma m_{t-1}\)
当前时刻的动量项指的是: \({m_t}\)
(上面的图只是为了助于理解,其中累积动量
7. Adagrad
SGD、SGD-M 和 NAG 均是以相同的学习率去更新 \(\theta\) 的各个分量 \(\theta_i\)。而深度学习模型中往往涉及大量的参数,不同参数的更新频率往往有所区别。对于更新不频繁的参数(典型例子:更新 word embedding 中的低频词),我们希望单次步长更大,多学习一些知识;对于更新频繁的参数,我们则希望步长较小,使得学习到的参数更稳定,不至于被单个样本影响太多。
Adagrad在 \(t\) 时刻对每一个参数 \(\theta_i\) 使用了不同的学习率,我们首先介绍 Adagrad 对每一个参数的更新,然后我们对其向量化。为了简洁,令 \(g_{t,i}\) 为在 \(t\) 时刻目标函数关于参数 \(θ_i\) 的梯度:
\[
g_{t, i} = \nabla_\theta J(\theta_{i})
\]
在 \(t\) 时刻,对每个参数 \(θ_i\) 的更新过程变为:
\[
\theta_{t+1, i} = \theta_{t, i} - \eta g_{t, i}
\]
对于上述的更新规则,在 \(t\) 时刻,我们要计算 \(θ_i\) 从初始时刻到 \(t\) 时刻的历史梯度平方和,来修正每一个参数 \(θ_i\) 的学习率:
\[
\theta_{t+1, i}=\theta_{t, i}-\frac{\eta}{\sqrt{v_{t, i i}+\epsilon}} \cdot g_{t, i}
\]
其中, \(v_t \in \mathbb{R}^{d\times d}\) 是对角矩阵,其元素 \(v_{t, ii}\) 为参数 第 \(i\) 维从初始时刻到 \(t\) 时刻的梯度平方和。即通过引入二阶动量,来调整每一个参数的学习率,等效为 \(\eta / \sqrt{v_t + \epsilon}\)
\[
v_t = \text{diag}(\sum_{i=1}^t g_{i,1}^2, \sum_{i=1}^t g_{i,2}^2, \cdots, \sum_{i=1}^t g_{i,d}^2)
\]
由于 \(v_t\) 的对角线上包含了关于所有参数 \(θ\) 的历史梯度的平方和,现在,我们可以通过 \(v_t\) 和 \(g_t\) 之间的元素向量乘法⊙向量化上述的操作:
\[
\theta_{t+1}=\theta_{t}-\frac{\eta}{\sqrt{v_{t}+\epsilon}} \odot g_{t}
\]
Adagrad算法的一个主要优点是无需手动调整学习率。在大多数的应用场景中,通常采用常数0.01。通过引入二阶动量,对于此前频繁更新过的参数,其二阶动量的对应分量较大,学习率就较小。这一方法在稀疏数据的场景下表现很好。但也存在一些问题:因为 \(\sqrt{v_t}\) 是单调递增的,会使得学习率单调递减至0,可能会使得训练过程提前结束,即便后续还有数据也无法学到必要的知识。
8. AdaDelta
Adadelta 是 Adagrad 的一种扩展算法,以处理Adagrad学习速率单调递减的问题。考虑在计算二阶动量时,不是计算所有的历史梯度平方和,而只关注最近某一时间窗口内的下降梯度,Adadelta将计算历史梯度的窗口大小限制为一个固定值 \(w\)
在 Adadelta 中,无需存储先前的 \(w\) 个平方梯度,而是将梯度的平方递归地表示成所有历史梯度平方的均值。在 \(t\) 时刻的均值 \(E[g^2]_t\) 只取决于先前的均值和当前的梯度(分量 \(γ\) 类似于动量项):
\[
E\left[g^{2}\right]_{t}=\gamma E\left[g^{2}\right]_{t-1}+(1-\gamma) g_{t}^{2}
\]
我们将 \(γ\) 设置成与动量项相似的值,即0.9左右。为了简单起见,我们利用参数更新向量 \(Δθ_t\) 重新表示SGD的更新过程:
\[
\begin{array}{c}{\Delta \theta_{t}=-\eta \cdot g_{t, i}} \\ {\theta_{t+1}=\theta_{t}+\Delta \theta_{t}}\end{array}
\]
我们先前得到的 Adagrad 参数更新向量变为:
\[
\Delta \theta_{t}=-\frac{\eta}{\sqrt{v_{t}+\epsilon}} \odot g_{t}
\]
现在,我们简单将对角矩阵 \(v_t\) 替换成历史梯度的均值 \(E[g^2]_t\):
\[
\Delta \theta_{t}=-\frac{\eta}{\sqrt{E\left[g^{2}\right]_{t}+\epsilon}} g_{t}
\]
由于分母仅仅是梯度的均方根(root mean squared,RMS)误差,我们可以简写为:
\[
\Delta \theta_{t}=-\frac{\eta}{R M S[g]_{t}} g_{t}
\]
作者指出上述更新公式中的每个部分(与SGD,SDG-M 或者Adagrad)并不一致,即更新规则中必须与参数具有相同的假设单位。为了实现这个要求,作者首次定义了另一个指数衰减均值,这次不是梯度平方,而是参数的平方的更新:
\[
E\left[\Delta \theta^{2}\right]_{t}=\gamma E\left[\Delta \theta^{2}\right]_{t-1}+(1-\gamma) \Delta \theta_{t}^{2}
\]
因此,参数更新的均方根误差为:
\[
R M S[\Delta \theta]_{t}=\sqrt{E\left[\Delta \theta^{2}\right]_{t}+\epsilon}
\]
由于 \(RMS[Δθ]_t\) 是未知的,我们利用参数的均方根误差来近似更新。利用 \(RMS[Δθ]_{t−1}\) 替换先前的更新规则中的学习率 \(η\),最终得到 Adadelta 的更新规则:
\[
\Delta \theta_{t}=-\frac{R M S[\Delta \theta]_{t-1}}{R M S[g]_{t}} g_{t}
\]
\[ \theta_{t+1}=\theta_{t}+\Delta \theta_{t} \]
使用 Adadelta 算法,我们甚至都无需设置默认的学习率,因为更新规则中已经移除了学习率。
9. RMSprop
RMSprop 是一个未被发表的自适应学习率的算法,该算法由Geoff Hinton在其Coursera课堂的课程6e中提出。
RMSprop和Adadelta在相同的时间里被独立的提出,都起源于对Adagrad的极速递减的学习率问题的求解。实际上,RMSprop 是先前我们得到的 Adadelta 的第一个更新向量的特例:
\[
\begin{array}{l}{E\left[g^{2}\right]_{t}= γ E\left[g^{2}\right]_{t-1}+(1-γ) g_{t}^{2}} \\ {\theta_{t+1}=\theta_{t}-\frac{\eta}{\sqrt{E\left[g^{2}\right]_{t}+\epsilon}} g_{t}}\end{array}
\]
同样,RMSprop 将学习率分解成一个平方梯度的指数衰减的平均。Hinton建议将 \(γ\) 设置为0.9,对于学习率 \(η\),一个好的固定值为0.001。
10. Adam
Adam 可以认为是 RMSprop 和 Momentum 的结合。和 RMSprop 对二阶动量使用指数移动平均类似,Adam 中对一阶动量也是用指数移动平均计算。
\[
m_t = \eta[ \beta_1 m_{t-1} + (1 - \beta_1)g_t ] \\
v_t = \beta_2 v_{t-1} + (1-\beta_2) \cdot \text{diag}(g_t^2)
\]
其中,初值
\[
m_0 = 0 \\
v_0 = 0
\]
注意到,在迭代初始阶段,\(m_t\) 和 \(v_t\) 有一个向初值的偏移(过多的偏向了 0)。因此,可以对一阶和二阶动量做偏置校正 (bias correction),
\[
\hat{m}_t = \frac{m_t}{1-\beta_1^t}
\]
\[
\hat{v}_t = \frac{v_t}{1-\beta_2^t}
\]
再进行更新,
\[
\theta_{t+1} = \theta_t - \frac{1}{\sqrt{\hat{v}_t} + \epsilon } \hat{m}_t
\]
可以保证迭代较为平稳。
11. NAdam
这里还没有太看懂,先把上面的优化算法完全理解了再说!
NAdam 在 Adam 之上融合了 NAG 的思想。
首先回顾 NAG 的公式,
\[ g_t = \nabla_\theta J(\theta_t - \gamma m_{t-1}) \]
\[ m_t = \gamma m_{t-1} + \eta g_t \]
\[ \theta_{t+1} = \theta_t - m_t \]
NAG 的核心在于,计算梯度时使用了「未来位置」\(\theta_t - \gamma m_{t-1}\)。NAdam 中提出了一种公式变形的思路,大意可以这样理解:只要能在梯度计算中考虑到「未来因素」,即能达到 Nesterov 的效果;既然如此,那么在计算梯度时,可以仍然使用原始公式 \(g_t = \nabla_\theta J(\theta_t)\) ,但在前一次迭代计算 \(\theta_t\) 时,就使用了未来时刻的动量,即 \(\theta_t = \theta_{t-1} - m_t\) ,那么理论上所达到的效果是类似的。
这时,公式修改为,
\[ g_t = \nabla_\theta J(\theta_t) \]
\[ m_t = \gamma m_{t-1} + \eta g_t \]
\[ \bar{m}_t = \gamma m_t + \eta g_t \]
\[ \theta_{t+1} = \theta_t - \bar{m}_t \]
理论上,下一刻的动量为 \(m_{t+1} = \gamma m_t + \eta g_{t+1}\),在假定连续两次的梯度变化不大的情况下,即 \(g_{t+1} \approx g_t\) ,有 \(m_{t+1} \approx \gamma m_t + \eta g_t \equiv \bar{m}_t\)。此时,即可用 \(\bar{m}_t\) 近似表示未来动量加入到 \(\theta\) 的迭代式中。
类似的,在 Adam 可以加入 \(\bar{m}_t \leftarrow \hat{m}_t\) 的变形,将 \(\hat{m}_t\) 展开有
\[
\hat{m_t} = \frac{m_t}{1-\beta_1^t} = \eta[ \frac{\beta_1 m_{t-1}}{1-\beta_1^t} + \frac{(1 - \beta_1)g_t}{1-\beta_1^t} ]
\]
引入
\[
\bar{m}_t = \eta[ \frac{\beta_1 m_{t}}{1-\beta_1^{t+1}} + \frac{(1 - \beta_1)g_t}{1-\beta_1^t} ]
\]
再进行更新,
\[
\theta_{t+1} = \theta_t - \frac{1}{\sqrt{\hat{v}_t} + \epsilon } \bar{m}_t
\]
即可在 Adam 中引入 Nesterov 加速效果。
12. 选择使用哪种优化算法
那么,我们应该选择使用哪种优化算法呢?如果输入数据是稀疏的,选择任一自适应学习率算法可能会得到最好的结果。选用这类算法的另一个好处是无需调整学习率,选用默认值就可能达到最好的结果。
总的来说,RMSprop是Adagrad的扩展形式,用于处理在Adagrad中急速递减的学习率。RMSprop与Adadelta相同,所不同的是Adadelta在更新规则中使用参数的均方根进行更新。最后,Adam是将偏差校正和动量加入到RMSprop中。在这样的情况下,RMSprop、Adadelta和Adam是很相似的算法并且在相似的环境中性能都不错。Kingma等人[9]指出在优化后期由于梯度变得越来越稀疏,偏差校正能够帮助Adam微弱地胜过RMSprop。综合看来,Adam可能是最佳的选择。
有趣的是,最近许多论文中采用不带动量的SGD和一种简单的学习率的退火策略。已表明,通常SGD能够找到最小值点,但是比其他优化的SGD花费更多的时间,与其他算法相比,SGD更加依赖鲁棒的初始化和退火策略,同时,SGD可能会陷入鞍点,而不是局部极小值点。因此,如果你关心的是快速收敛和训练一个深层的或者复杂的神经网络,你应该选择一个自适应学习率的方法。
13. 可视化分析
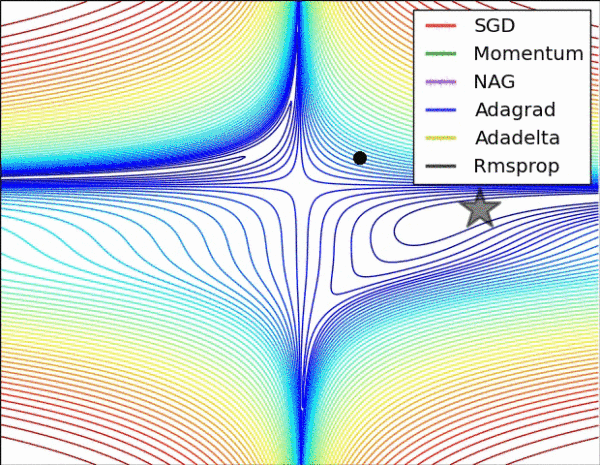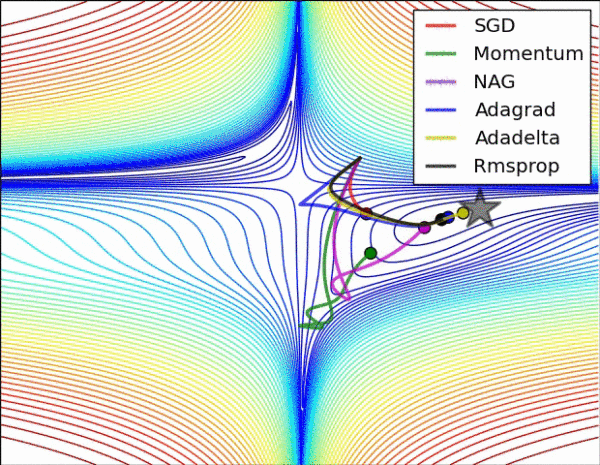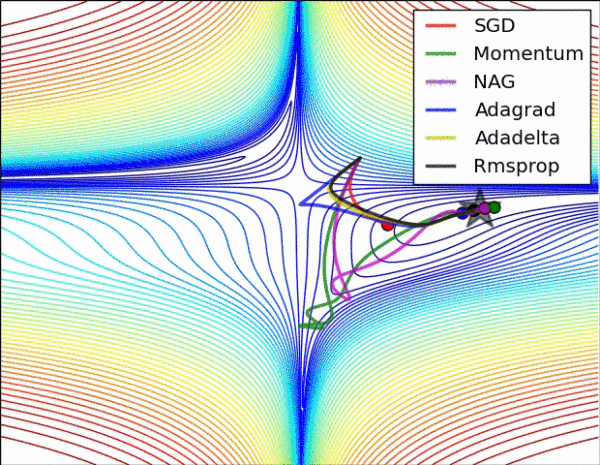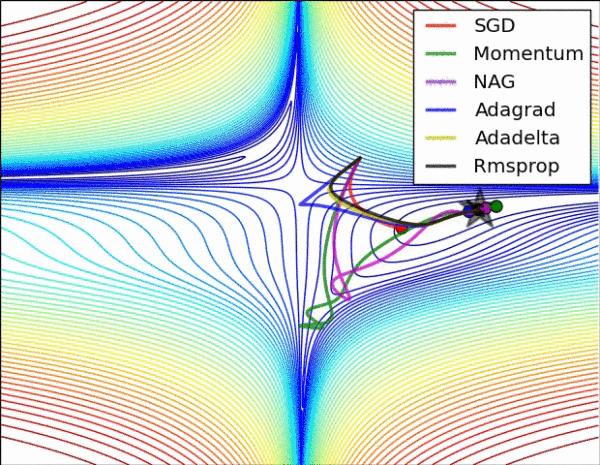 |
|
|---|---|
| 图 3: SGD optimization on loss surface contours | 图 4: SGD optimization on saddle point |
图 3 和图 4 两张动图直观的展现了不同算法的性能。(Image credit: Alec Radford)
图 3 中,我们可以看到不同算法在损失面等高线图中的学习过程,它们均同同一点出发,但沿着不同路径达到最小值点。其中 Adagrad、Adadelta、RMSprop 从最开始就找到了正确的方向并快速收敛;SGD 找到了正确方向但收敛速度很慢;SGD-M 和 NAG 最初都偏离了航道,但也能最终纠正到正确方向,SGD-M 偏离的惯性比 NAG 更大。
图 4 展现了不同算法在鞍点处的表现。这里,SGD、SGD-M、NAG 都受到了鞍点的严重影响,尽管后两者最终还是逃离了鞍点;而 Adagrad、RMSprop、Adadelta 都很快找到了正确的方向。
关于两图的讨论,也可参考[2]和[8]。
可以看到,几种自适应算法在这些场景下都展现了更好的性能。
14. Reference
- https://blog.csdn.net/google19890102/article/details/69942970
- 翻译的一篇博客
- 一个框架看懂优化算法之异同 SGD/AdaGrad/Adam
- 从 SGD 到 Adam —— 深度学习优化算法概览(一)
- http://cs231n.github.io/neural-networks-3/
- An overview of gradient descent optimization algorithms [paper]
- 上面博客看不懂就参考这篇博客:An overview of gradient descent optimization algorithms [blog]
- https://www.cnblogs.com/xinchrome/p/4964930.html
- http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
- https://zhuanlan.zhihu.com/p/27449596
- https://juejin.im/entry/5983115f6fb9a03c50227fd4
- https://www.cnblogs.com/denny402/p/5074212.html
- https://zhuanlan.zhihu.com/p/27449596